这篇文章是解析CNN在NLP中的最基础的应用,将会一点一点地解析每一个函数和变量的关系
1.整体结构的概念理解:
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
2.具体函数实现的解析:
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/
本文将要介绍:
1. 如何构建CNN在NLP中的模型
2. 如何在训练这个模型
3. input中如何使用pre-trained word embedding
4. 二层CNN模型的尝试
1. 如何构建CNN在NLP中的模型
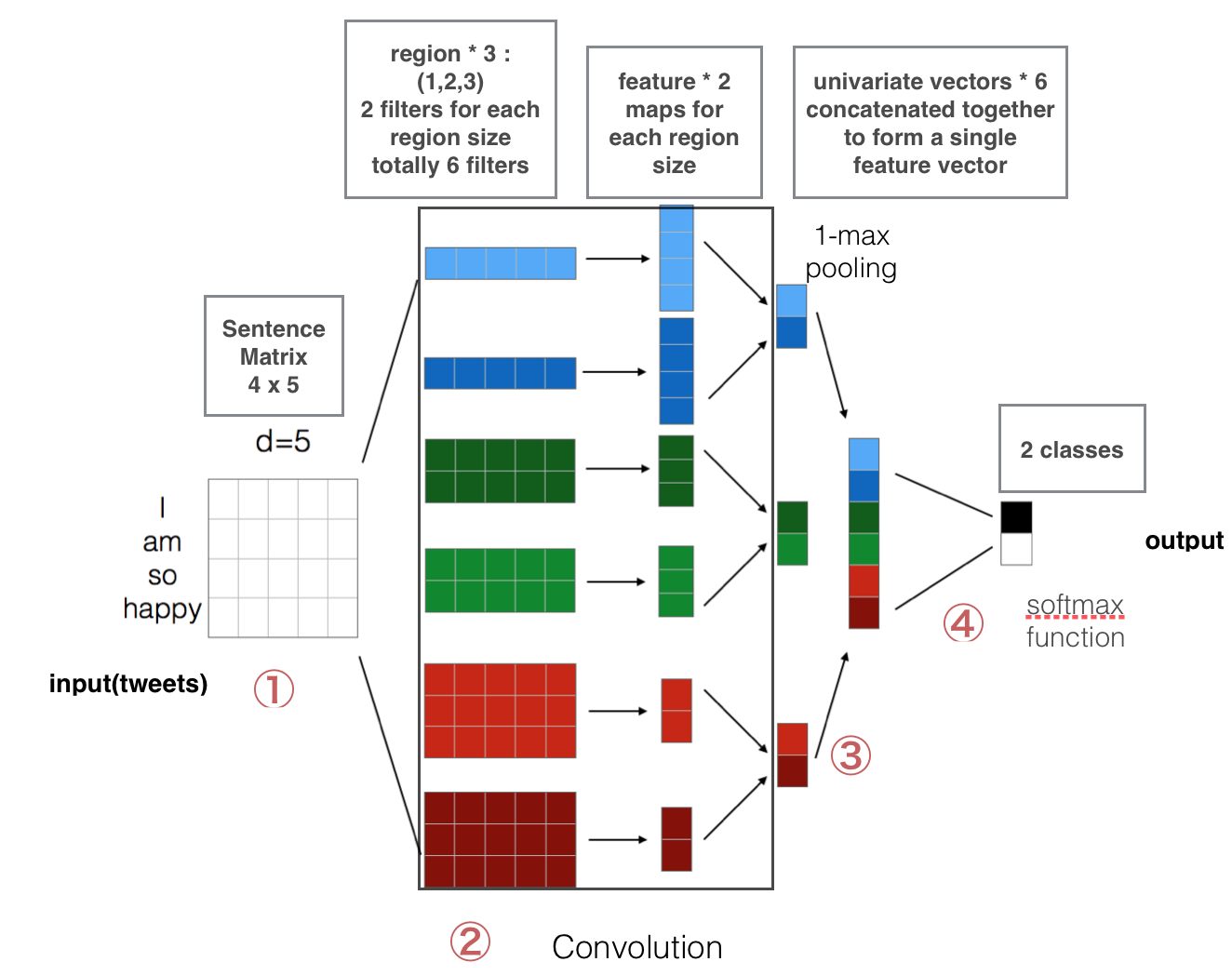
首先,我们先来看一下整篇代码的结构:
- 第一层是把embeds words转换层low-dimensional vectors(低纬向量)
- 第二层使用多个filter size去卷积我们第一层的所输出的vectors
- 第三层我们使用max-pooling后把所有的feature连接,得到一个long featurevector,这里我们加入dropout 的正规化(regularzation)
- 最后一层,我们使用softmax去识别我们的result。
1. 首先声明一个TextCNN的类
|
|
2. 声明数据变量和结果还有dropout的占位符
|
|
(1)placeholder的作用在前文中有介绍,就不累赘了。
(2)第二个参数是我们input的tensor,这里可以看到,x的input格式是int32,而y的input格式是float32。
(3)None表示训练的时候,dimension可以是任何的参数,这里是规定batch size的大小,我们可以在训练的时候规定它的大小。
3. 构建我们的第一层,embedding layer
这里我们是把词汇转换层低维度的vector。(后面我们会介绍如何用pre-trained vector去作为我们的input vector)。
|
|
这里我们先介绍一下python中with的用法。
很多任务中,我们需要事先声明变量然后,事后做清理工作,那么python中的with就很好的提供了这一种处理方式。
with语句可以很好的解决两个问题:(让代码更简练,产生异常时,清理工作更简单)
(1)如果事后忘记清理某些变量时
(2)文件发生异常时,可以抛出问题。
with···as···相当于try…except…finally…
如何用:
with 后面直接写需要调用的函数,需要的多个的话,用“,”隔开
|
|
W Variable的声明
这里声明W是我们将会在训练中学习的嵌入式矩阵。用random uniform分布初始化。
embedded_chars是创造实际的嵌入式操作。这里最后的结果是3维的tensor。
embedded_chars_expaned给三维加上一维的操作。(因为之后的con2d函数要求4维的输入)
|
|
4. 构建我们的第二层,Convolution layer和maxpooling layer
现在我们来部署一下我们的第二层,Convolution layer。这里我们会用到很多不同的filter,每一个filter去convolute 整个map的时候,会产生很多不同的tensor。
给每一个filter创造一个layer,之后用max-pooling 去合并整个结果,得到一个大的feature vector。
|
|
这里的W是我们的filter的矩阵(与embedding layer中的W不同,那里是embedding layer中的,这里是filter中的)。h是我们当前for循环中的filter_size的输出结果,通过非线性函数relu之后的结果。
结合所有的max pooling得到的结果,在pooled_outputs数组里面。